Who is Liora Evenshadow? Your custom offline $0 cost AI whisperer that knows your secrets.
Initially published on Medium
You don’t call it. You just type your sentence, and when the cursor stops, suddenly, the next line appears by itself, as if someone already knew what you were going to write. It is here. It is always here. No network. No server. It knows what you need. It knows only what it should know — and it will never tell anyone.
There are already plenty of articles about various tools, but I would like to share my invaluable experience of integrating solutions like LM Studio and AnythingLLM (along with VS Code IDE and the Continue plugin ). This experience could be highly useful for a wide range of potential users, including beginner business analysts, testers, support engineers, and others…
What I want? I want a local LLM that I can instantly feed with interesting to me knowledge without the need for expensive training.
Among the vast number of existing online tools, there is often no AI-based solution that fully meets all your needs.
Now, imagine you are a beginner, but you want to provide an AI tool with a bit of context — such as a set of documents for analysis and a specialist’s instruction manual in the form of one or multiple documents — to help it:
-
Conduct business analysis of requirements based on the given context.
-
Design test cases using both the provided context and specific expertise from the instruction manual.
-
Perform static code analysis to identify vulnerabilities according to your unique security guidelines.
How do you think the ideal solution capable of handling any of these tasks should look like?
Here’s the set of requirements that, in my view, brings us as close as possible to the perfect solution for my use cases:
-
Security — You don’t want to send sensitive case data over the internet to a third-party provider.
-
Local access — You want to interact with the model on your local computer or within your isolated intranet or private virtual network.
-
Dynamic knowledge — You need the model not only to rely on its pre-trained knowledge but also to quickly acquire information about new contexts relevant to you.
-
No costly training — You don’t have the resources to invest in expensive machine learning or mastering its complex methodologies.
-
Instant updates — You dream of a setup where any useful material you come across — be it online or a book stored on your local drive — can instantly be transferred into your model’s knowledge.
-
Flexible model selection — You want the freedom to choose any model that best suits your task and hardware.
-
Easy deployment and integration — You need to have unified deployment way to replicate it and to support anywhere.
-
Cost — solution is better to be non-expensive or free.
Below is an example of my journey of assembling solution architecture from existing tools.

As precondition I need some LLM runtime which supports RAG RAG (Retrieval-Augmented Generation) is an AI framework that enhances text generation by retrieving relevant information from external sources before generating responses, improving accuracy and reducing hallucinations.
Then…
-
LM Studio — has it’s own RAG but it requires some additional work to make it usable outside the LM Studio UI chat itself. The feature I need to take it from is ability to download any preferred model and spin it up locally.
- AnythingLLM — amazing tool:
- It’s able to use runtimes from a range of providers including our local LM Studio one.
- Has it’s own vector DB and bundle out of the box features that handle RAG accurately.
- Has useful long memory option and ability to organize RAG context into different workspaces.
- Equipped with ability to fill in RAG context from files, folders and even WEB-page via Browser extension.
-
Docker — to spin up AnythingLLM with API-server enabled.
- [VS Code IDE *](https://code.visualstudio.com/)and the Continue plugin to research if the RAG knowledge will be available to access context-based knowledge via AnythingLLM API-server. Of course the @Codebase *Continue plugin indexing mechanism is enough in a lot of cases but I want to have a real and flexible RAG on top of a base.
So lets begin with deployment/integration/verification scenario…
- Run ‘deepseek’ based LLM inside LMStudio as server (HOW TO)
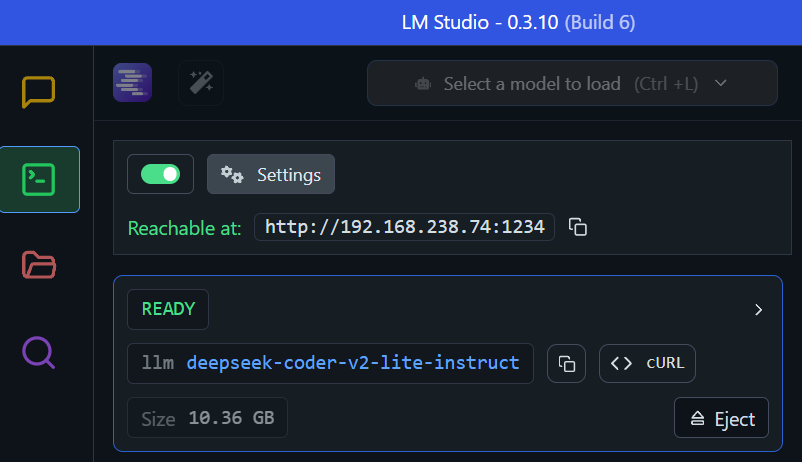
- Run Anything LLM inside Docker engine (HOW TO).
-
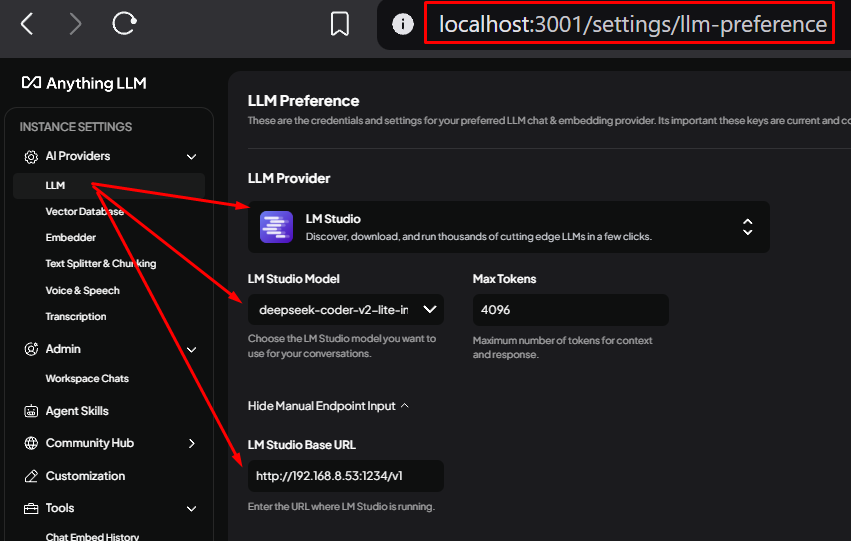
Correctly set up LLM Provider
-
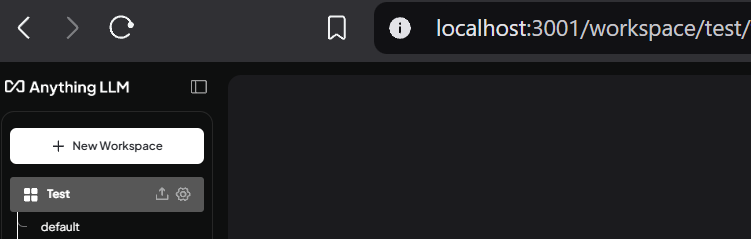
Create new workspace with name Test
-
Enable API access with API-key (HOW TO)
- Let’s do some reverse engineering to extract the workspace ID we’ll use and enriching with new knowledge from: 🔗http://localhost:3001/api/workspaces
- Grab Open AI Compatible endpoint root from: 🔗http://localhost:3001/api/docs/#/
- Install Continue plugin in the VS Code IDE and adjust plugin [config.json] configuration:
{
...
"models": [
{
"apiBase": "http://localhost:3001/api/v1/openai/",
"model": "test",
"title": "AnythingLLM",
"provider": "openai",
"apiKey": "F2J195C-2R0MVP0-QYDH124-50WKQV0"
}
],
...
}
- Install AnythingLLM Browser Companion extension to your browser. We will use it to quickly verify our RAG-equipped instrument is really able to access and operate with some unique information.
- Create some unique information and publish it to the WEB (you can simply use any local document you prefer. WEB example is to just for some clarity of illustration. In my case I just published Google Spreadsheet contains information about fictional character Liora Evenshadow)
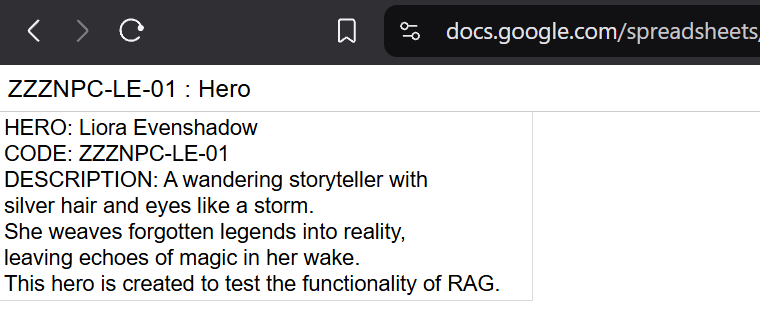
— — — — — — — — — —== NOW THE MAGIC BEGINS == — —— — — — — — —
- Embed information about our character into workspace
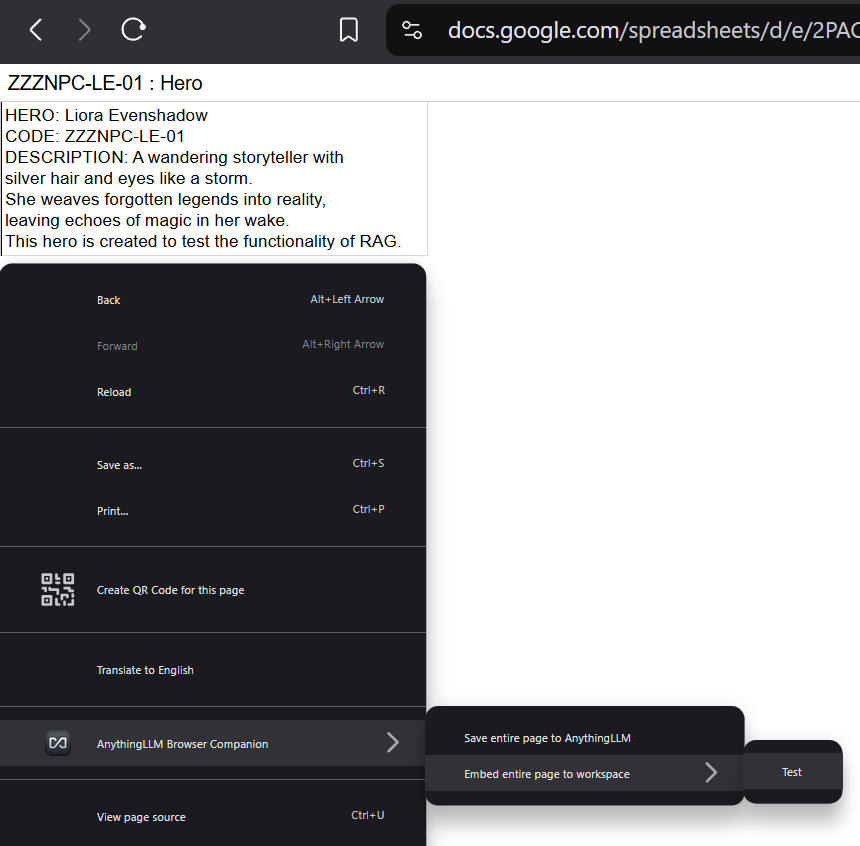
Who is Liora Evenshadow?
Let’s try to give this answe just inside the VS Code Continue plugin chat

Summary
I hope you don’t find this article too superficial, as the integration of tools like LM Studio and Anything LLM may seem obvious to some users. However, my goal was simply to convey the idea that ready-to-use solutions already exist — solutions that can be seamlessly integrated into an infinite number of workflows, making them accessible to specialists of all kinds and “calibers”.
In my case, this resulted in a fully functional and secure offline LLM with zero cost — that one who knows who Liora Evenshadow is… and a lot of my other secrets. 😉
P.S.
This wasn’t supposed to work out of the box… but it did. 🚀🚀🚀
What was I missing in AnythingLLM?
Maybe I just didn’t find it in the official documentation, but one thing remains unclear to me — how can I manage workspace contexts through OpenAI API-compatible endpoints? Ideally, I’d like to build a flexible system where different contexts are routed to different groups, allowing that knowledge to be separated at the client level (IDE plugin in my case).
But that’s another time story… One thing is definitely clear!
AnythingLLM+LM Studio is a game-changer combination to me for today. 🚀🚀🚀
Solutions investigated: LMStudio, AnythingLLM, Ollamа, Jan, GPT4All, LocalAI, (n) of IDE plugins. Illustrations: app.cloudcraft.co + black-forest-labs/FLUX.1-schnell